
NLP to Identify Teen Interests
Metis Module 5 - NLP & Unsupervised Learning
YouTube video transcripts as an unsupervised NLP problem.
ABSTRACT
For this project, I used Python Package Index’s youtube_transcript_api to collect the transcript data from over one thousand YouTube videos targeted to the teenage demographic in order to better understand teenage interests, as well as word and phrase usage. To do this, I used natural language processing techniques such as text preprocessing with NLTK, dimensionality reduction with Non-Negative Matrix Factorization, and sentiment analysis with TextBlob. I was able to extract fifteen unique topics from the dataset, uncovered a handful of formerly unfamiliar words/YouTube celebrities to me, and exposed interests and YouTube subcultures of which I was not previously aware.
BACKGROUND
As I grow older, I sadly realize that I am no longer aware of the interests, as well as some of the words and phrases used by younger generations. Similar to me with my parents, my children will one day say something that will cause me to respond with, “what are you talking about?” In an attempt to curb this small but present semantic divide between young and old, I wanted to explore YouTube video transcript data in order to learn more about the type of interests, words, and phrases teens are using.
MATERIALS AND METHODS

DATA COLLECTION
In order to get a ‘truer’ representation of the types of videos that teens might watch I created a supervised children’s YouTube account: a new feature offered by Google that is still in beta testing. This account has limitations on the types of videos its user can view, restricting exposure to content one could deem as ‘adult’ in nature. I then subscribed to over fifty channels that various online publications highly rated as must watch YouTube channels for teens.

With a custom Selenium script, I was able to pull all the URLs of each video recommended to the YouTube account from its main page. After saving the URLs to a csv, I used the video identification portion of the URL to pull 1524 teen centric YouTube video transcripts and their corresponding metadata with the Python Package Index’s YouTubeTranscriptApi (transcripts) and Google Developer’s YouTube API (metadata).
The metadata consisted of:
• Video title
• Date uploaded
• Video views
• Video likes
• Video dislikes (oddly enough, deprecated this week)
• Video comment count
• Video length
• Video description
• Video channel
• Video country
• Total channel views
• Total channel subscribers
• Total channel videos
DATA CLEANING AND TEXT PREPROCESSING
I used Pandas to clean the metadata and perform simple transformations such as date conversion, remove videos posted before 2015, and even created a custom function to fix the vidLength column. Furthermore, I removed videos that had less than twenty words in their transcript, as these would provide no real context, and which might cause a model to assign them to the wrong topic.
In text preprocessing I used Scikit-Learn's ENGLISH_STOP_WORDS list in addition to my own list of stop words to remove frequently occurring English words that would provide little context and create too much noise in my analysis. I also lemmatized all words (the process of grouping together the inflected forms of a word into a single item), stripped all white spaces, and lowercased all letters.
I also used Scikit-Learn's CountVectorizer (I used for “LDA”) and TfidfVectorizer (I used for “NMF”) to transform the raw text into meaningful feature vectors of numbers, also known as a document-term matrices. Within this process I created bigrams (a sequence of two adjacent elements from a string of tokens), removed additional stop words, set a max and min threshold to reduce the representation of overrepresented/underrepresented words within the matrix, and used a max feature creation of one thousand.
ASSUMPTIONS/BIAS IN THE DATA
The types of channels the YouTube account subscribed to definitely influenced the videos YouTube recommended. While I tried to use the ‘popular’ approach and subscribed to highly recommended channels/channels with high subscribership, and worked to ensure diversity in the account’s subscribership: the data was biased. I only had 1500 videos, and of those videos, several channels were overrepresented. More data and a different approach to URL acquisition would yield more exposure to a greater range of subcultures within the YouTube domain and thus (hopefully) improve latent topic discovery.
RESULTS
I performed dimensionality reduction/topic modeling with Latent Dirichlet allocation (“LDA”) and Non-Negative Matrix Factorization (“NMF”). I started my unsupervised exploration with the CountVectorizer document term matrix and LDA (a generative probabilistic model used to find latent themes in collections of discrete data). Additionally, I used pyLDAvis, an interactive topic model visualization tool for Python, to look at the different latent groupings of topics generated by LDA. I tested a range of features-returned from four to twenty. I had difficulty isolating distinct topics, however, I was able to use pyLDAvis to reveal more words that I needed to add as stop words. Several words in particular, like ‘button,’ ‘subscribe,’ and ‘like,’ are domain specific to YouTube—many content creators often ask viewers to click the ‘like button’ and to ‘subscribe’ to their channel—which were added as stop words.
Frustrated with LDA, I decided to try NMF (a model that factorizes high-dimensional vectors into a lower-dimensional representation) with the TfidfVectorizer document term matrix. I figured NMF would provide easier interpretation—and I was right. After I tested different values for features-returned and adjusted my stop word’s list, I was able to settle in on fifteen distinct topics. To find the topics, I primarily used the videos’ titles in each topic and the words that defined each topic to interpret and summarize the list of topics.
| Document-Term Matrix | TfidfVectorizer |
| Model | Non-Negative Matrix Factorization (“NMF”) |
| Topics Returned | 15 |
My final list of topics:
- Video Reviews – fast-takes, mockery
- Hair Care
- Prizes – giveaways, individual challenges
- Food – cooking, food reviews
- Minecraft – video game
- Games – anything with game in it: Squid Games, Football
- School – high school, college
- Educational – NASA, BLM, tell all’s
- Pregnancy – matured vloggers sharing their birthing stories
- Dance/Music – musicals, music videos, dance tutorials
- Halloween – haunted houses, pumpkins
- Clothes
- Challenges– contestants competing for prizes
- Beauty Care – makeup, purse reveals
- Christmas
In conjunction with the metadata, I was able to determine that the topic with the greatest representation within the dataset was Beauty Care, the least was Pregnancy. The topic with the greatest average ‘likes’ was Prizes and the topic with greatest average ‘dislikes’ was Christmas—surprisingly. Prize videos also had the highest average views, whereas Halloween videos had the least. Pregnancy videos had the highest average like to dislike ratio.
Some words unbeknownst to me prior to this project resided in the Minecraft topic, which is a highly creative video game involving the construction of mini worlds using blocks. Words like ‘diamond,’ ‘nether,’ and ‘creeper’ are all specific to that game. Furthermore, in the Prizes category, the names of celebrities from the ‘Mr. Beast’ channel defined that topic. This channel’s content primarily involves prize giveaways. Also, prior to this project, I had no idea who Mr. Beast was or that he had one of the most popular YouTube channels. Lastly, in the Beauty Care topic, there was a popular channel within my dataset that interviewed celebrities while they revealed the contents of their purse/bag, which I thought was a fun idea.
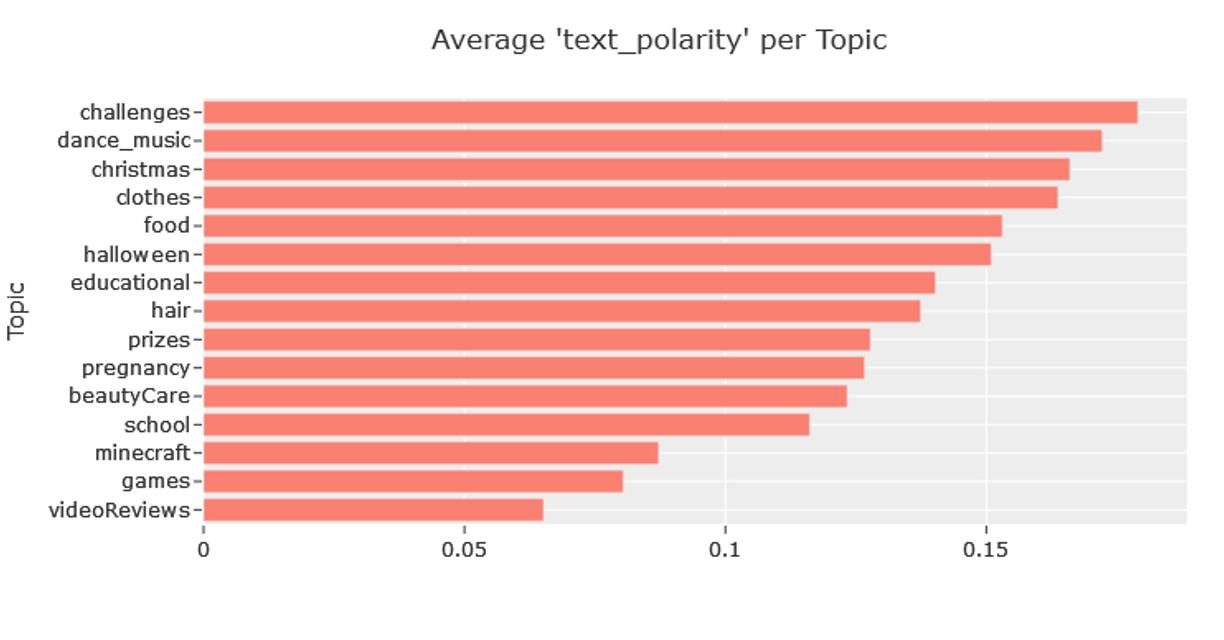
In terms of sentiment, I used TextBlob’s sentiment functionality to determine the polarity of each document in my dataset (-1 being negative and +1 being positive). Topics pertaining to Challenges, Dance/Music, and Christmas had the highest average sentiment, whereas topics pertaining to Minecraft, Games and Video Reviews had the lowest. This makes sense because challenges (at least on the Mr. Beast channel) usually result in a winner of a prize, which is positive. Whereas review videos can be more negative because they tend to mock the people in the videos.
CONCLUSION
We can use unsupervised learning and natural language processing to identify unique latent topics within a corpus of teen centric data to surface interests, words, and phrases particular to teens. With just a simple dataset from one source, I was able to use topic modeling to identify unfamiliar words, cultures, interests and figures I was previously unaware of, but that are important to teens.
BUSINESS USE CASE
In terms of a business use case, extracting, synthesizing, and providing information like this could be immensely helpful to parents, educators, therapists, and psychologists to better understand and relate to the teens in their lives.
FUTURE WORK
In order to improve upon this model, more data and a more diverse body of data would help to uncover more unique latent topics. To get more data, I would like to explore text data availability for Tik Tok, Discord, Reddit, and Instagram as well as get more video text data from YouTube. Furthermore, because communication on boards and videos can be in the form of images and video (no text or spoken language), the incorporation of deep learning and image recognition would be helpful to further identify teen specific interests and topics.
Check out the code for this project on GitHub!